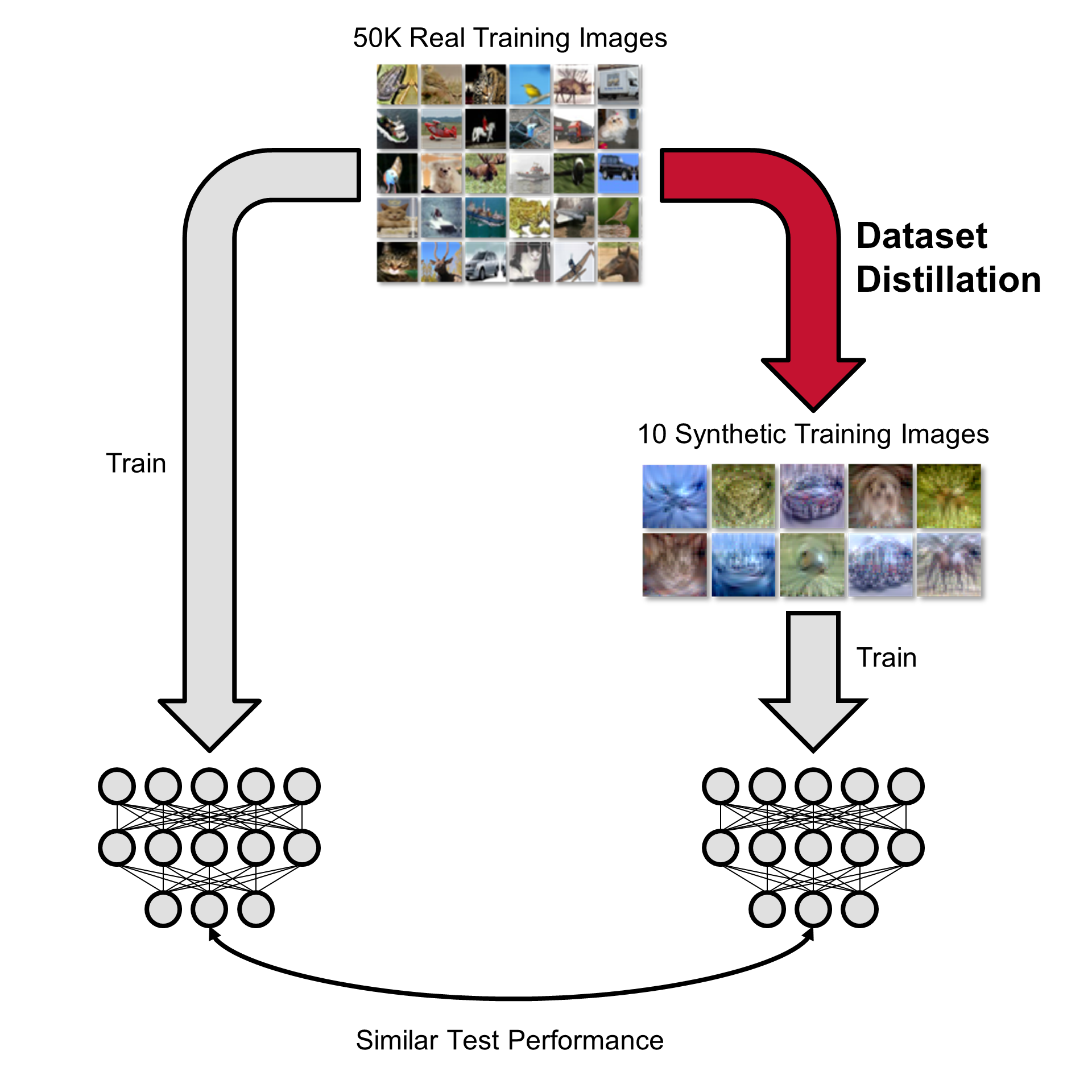
Dataset distillation is the task of synthesizing a small dataset such that a model trained on the synthetic set will
match the test accuracy of the model trained on the full dataset.
In this paper, we propose a new formulation that optimizes our distilled data to guide networks to a similar state
as those trained on real data across many training steps.
Given a network, we train it for several iterations on our distilled data and optimize the distilled data with
respect to the distance between the synthetically trained parameters and the parameters trained on real data. To
efficiently obtain the initial and target network parameters for large-scale datasets, we pre-compute and store
training trajectories of expert networks trained on the real dataset.
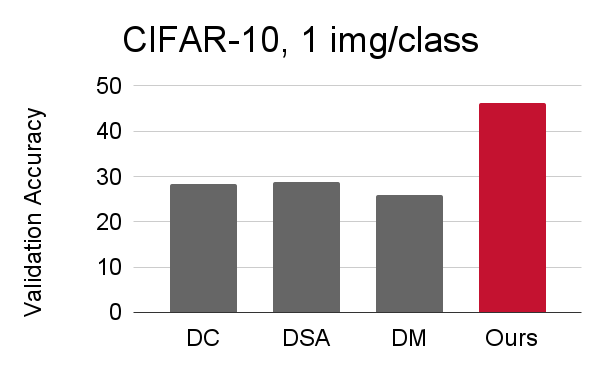
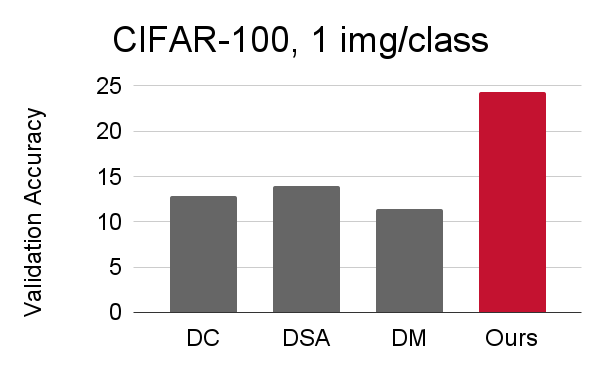
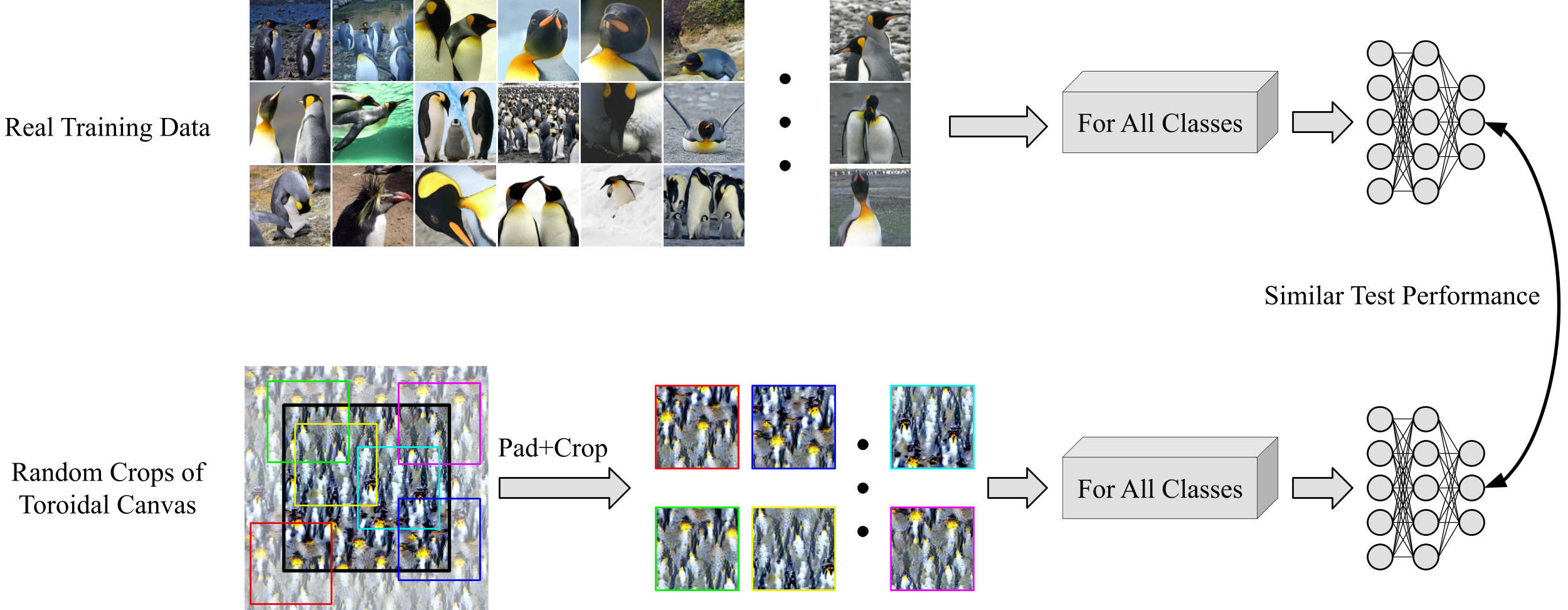
Our method handily outperforms existing methods and also allows us to distill higher-resolution visual data.
32x32 Images |
| CIFAR-10: 1, 10, 50 images/class |
CIFAR-100: 1, 10, 50 images/class |
| CIFAR-10 ZCA: 1, 10, 50 images/class |
CIFAR-100 ZCA: 1, 10, 50 images/class
|
64x64 Images |
| Tiny ImageNet: 1, 10, 50 images/class |
128x128 Images |
| ImageFruit: 1, 10 images/class |
ImageSquawk: 1, 10 images/class |
| ImageWoof: 1, 10 images/class
|
ImageMeow: 1, 10 images/class
|
| ImageNette: 1, 10 images/class |
ImageBlub: 1, 10 images/class |
| ImageYellow: 1, 10 images/class |